The recent advancements in visual reasoning capabilities of large multimodal models (LMMs) and the semantic enrichment of 3D feature fields have expanded the horizons of
robotic capabilities. These developments hold significant potential for bridging the gap between high-level reasoning from LMMs and low-level control policies utilizing 3D feature fields.
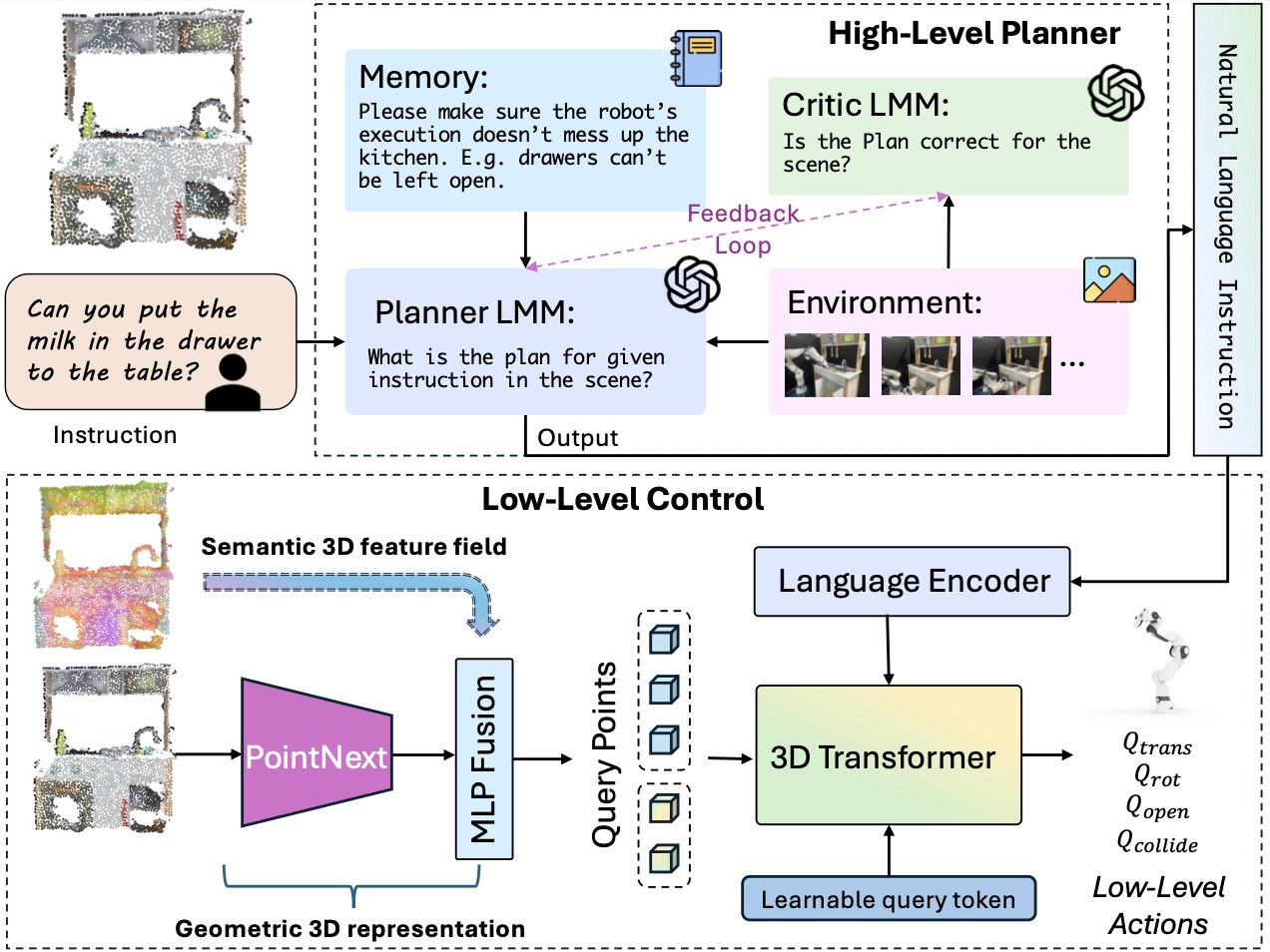
In this work, we introduce LMM-3DP, a framework that can integrate LMM planners and 3D skill Policies. Our approach consists of three key perspectives: high-level planning, low-level control,
and effective integration. For high-level planning, LMM-3DP supports dynamic scene understanding for environment disturbances, a critic agent with self-feedback, history policy memorization,
and reattempts after failures. For low-level control, LMM-3DP utilizes a semantic-aware 3D feature field for accurate manipulation. In aligning high-level and low-level control for robot actions,
language embeddings representing the high-level policy are jointly attended with the 3D feature field in the 3D transformer for seamless integration. We extensively evaluate our approach across multiple skills and long-horizon tasks in a real-world kitchen environment.
Our results show a significant 1.45x success rate increase in low-level control and an approximate 1.85x improvement in high-level planning accuracy compared to LLM-based baselines.